Artificial Intelligence researcher with expertise on symbolic and sub-symbolic techniques (from Machine Learning to Knowledge Representation). My major area of interest is Natural Language Processing, particularly Conversational AI and its intersection with knowledge graphs.
Selene Báez Santamaría
Dynamic and Distributed Information Systems of Prof. Dr. Abraham Bernstein
University of Zurich
Binzmühlestrasse 14
8050 Zürich
Switzerland
selene.baezsantamaria[at]uzh.ch
PhD • March 2020 - December 2024
M.Sc. Degree in Artificial Intelligence (Cum Laude) • 2015 - 2017
B.Sc. Degree in Cognitive Systems: Computational Intelligence & Design (Graduated with Distinction) • 2011 - 2014
AI Researcher • June 2019 - February 2020
Data Scientist • October 2017 - June 2019
University Research Fellow • September 2017 - August 2019
Watson Demo Intern • July 2016 - January 2017
I am determined and goal-oriented with strong analytical and critical thinking. I thrive collaborative workplaces that promote self-growth through challenging projects.
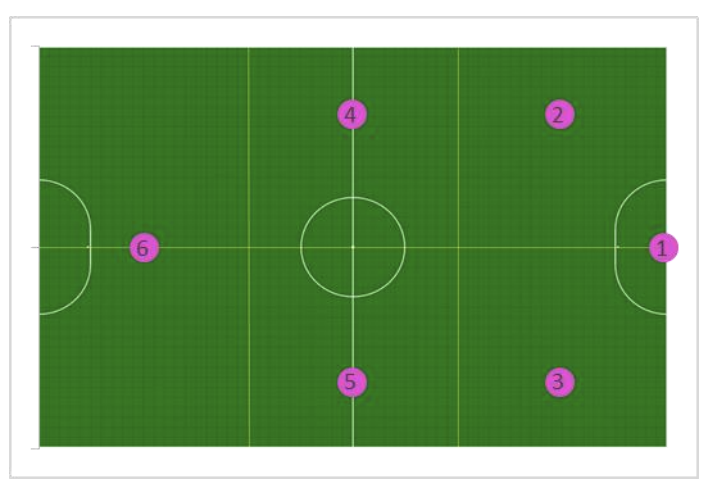
The goal of this project is to predict the opponent’s configuration in a RoboCup SSL environment. For simplicity, a Markov model assumption is made such that the predicted formation of the opponent team only depends on its current formation. The field is divided into a grid and a robot state per player is created with information about its position and its velocity. To gather a more general sense of what the opposing team is doing, the state also incorporates the team’s average position (centroid). All possible state transitions are stored in a hash table that requires minimum storage space. The table is populated with transition probabilities that are learned by reading vision packages and counting the state transitions regardless of the specific robot player. Therefore, the computation during the game is reduced to interpreting a given vision package to assign each player to a state, and looking for the most likely state it will transition to. The confidence of the predicted team’s formation is the product of each individual player’s probability. The project is noteworthy in that it minimizes the time and space complexity requirements for opponent’s moves prediction.
Robots, UBC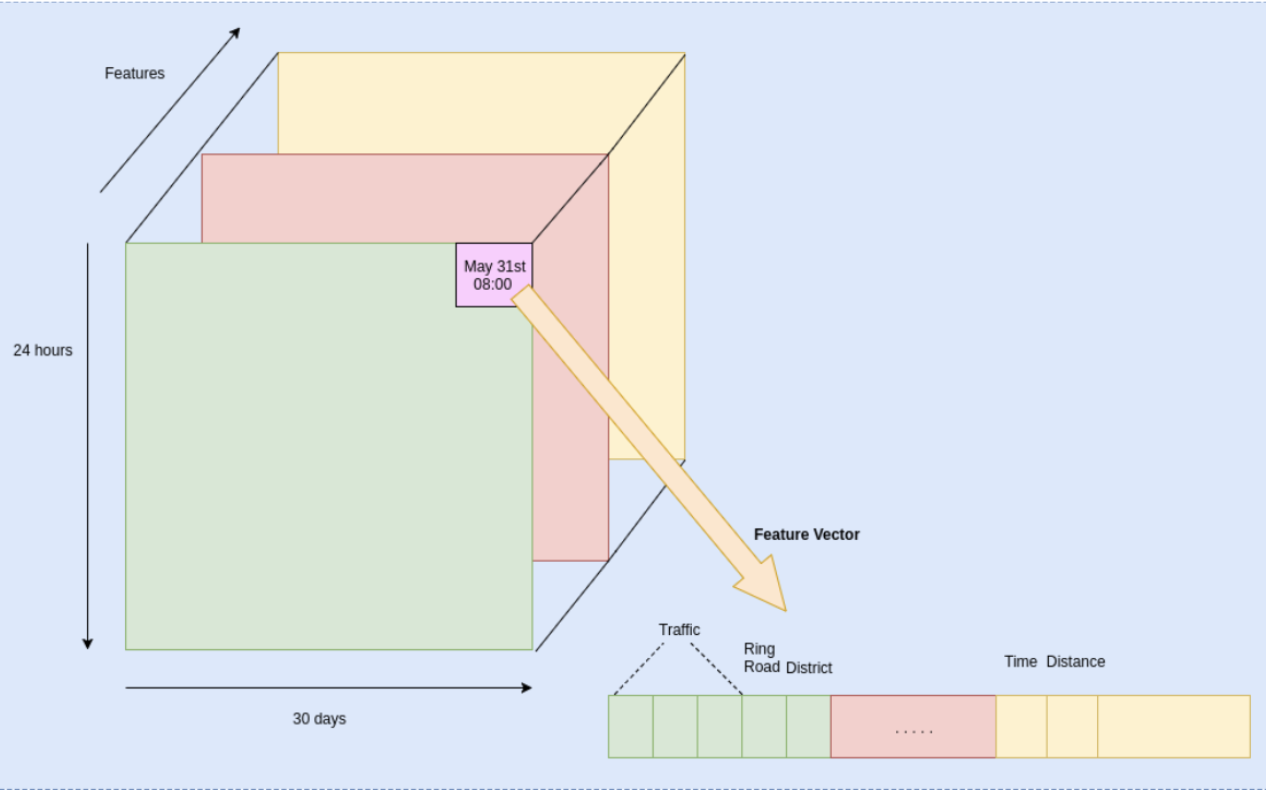
This project proposes a three dimensional representation for pattern recognition of traveling behavior. We carry out dimensionality reduction on this representation and compare supervised and unsupervised learning tasks for recognizing typical behaviors in users. First, ensemble models aid us on the task of binary classification of commuters (as labeled by self-reported survey data). Then, we characterize users by encoding their behaviors using an convolutional autoencoder, and performing clustering. The city of Beijing, China is posed as an use case for the project. With 75\% average accuracy, our results on binary classification are not competitive with other studies on the field. However, labeled data obtained via surveys is typically noisy, and thus a high classification rate does not necessarily benefit Transportation specialists. In contrast, we found 7 distinct user groups on the clustering task leading to a better understanding of the users' routines and needs. In conclusion, we believe state of the art techniques for unsupervised learning and local representations should be exploited in this domain. As such, the knowledge extracted can lead to better target policies and services in pro of improving the transportation network in large and complex cities.
Machine Learning, VUThis paper presents a novel method for mining the individual travel behavior regularity of different public transport passengers through constructing travel behavior graph based model. The individual travel behavior graph is developed to represent spatial positions, time distributions, and travel routes and further forecasts the public transport passenger’s behavior choice. The proposed travel behavior graph is composed of macro-nodes, arcs, and transfer probability. Each macro-node corresponds to a travel association map and represents a travel behavior. A travel association map also contains its own nodes. The nodes of a travel association map are created when the processed travel chain data shows significant change. Thus, each node of three layers represents a significant change of spatial travel positions, travel time, and routes, respectively. Since a travel association map represents a travel behavior, the graph can be considered a sequence of travel behaviors. Through integrating travel association map and calculating the probabilities of the arcs, it is possible to construct a unique travel behavior graph for each passenger. The data used in this study are multimodal data matched by certain rules based on the data of public transport smart card transactions and network features. The case study results show that graph based method to model the individual travel behavior of public transport passengers is effective and feasible. Travel behavior graphs support customized public transport travel characteristics analysis and demand prediction.
Graph Technologies, BJUT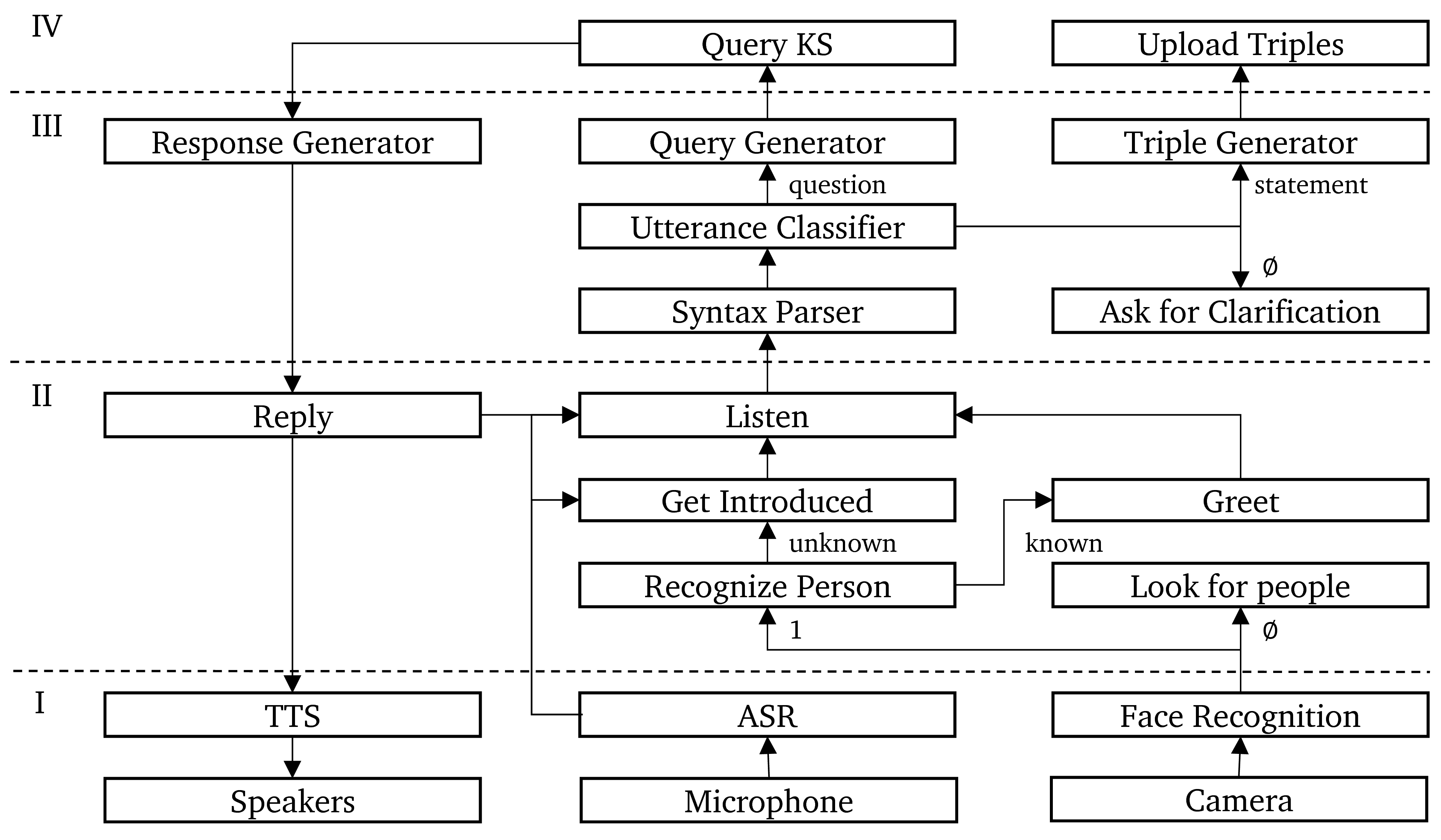
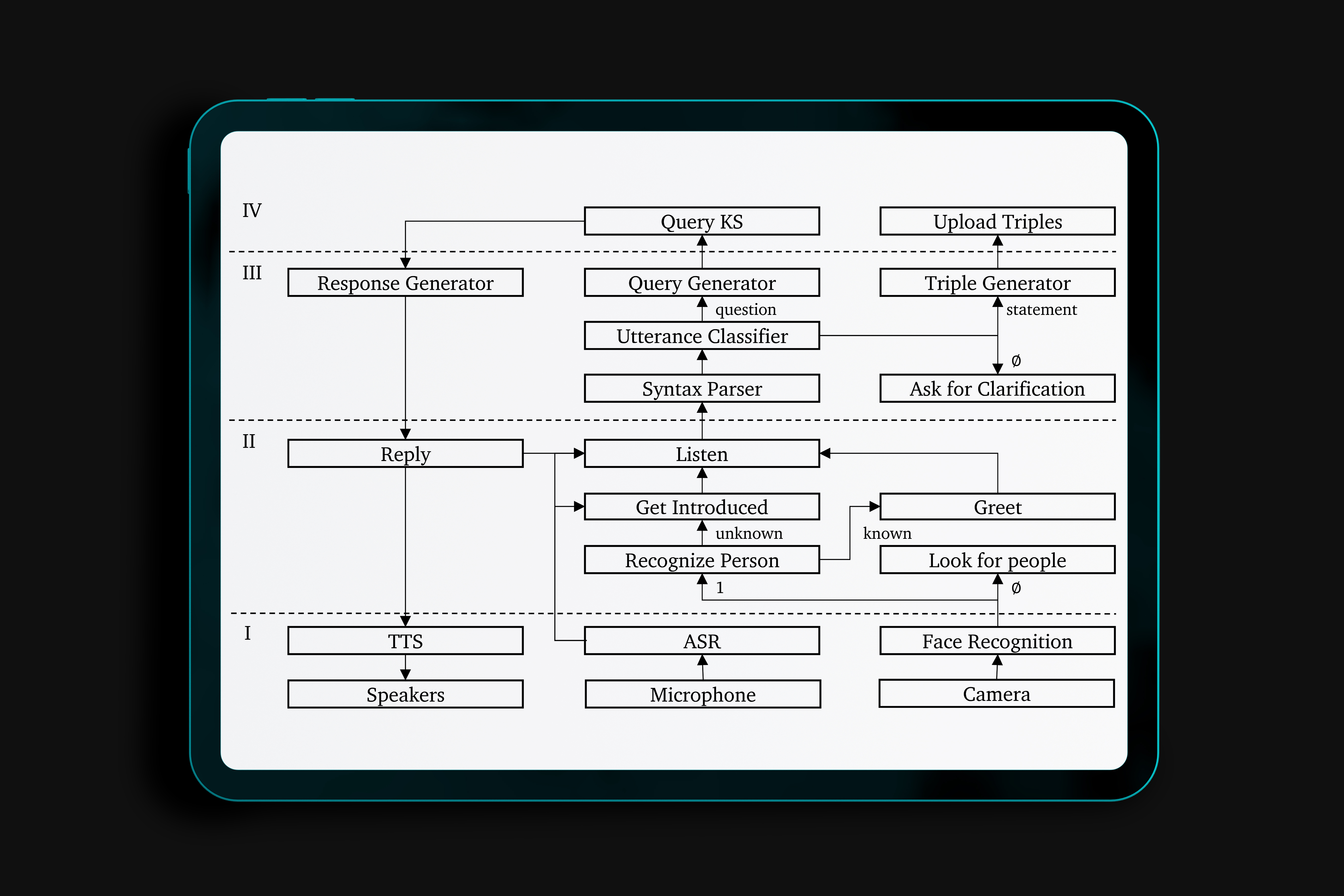
Our state of mind is based on experiences and what other people tell us. This may result in conflicting information, uncertainty, and alternative facts. We present a robot that models relativity of knowledge and perception within social interaction following principles of the theory of mind. We utilized vision and speech capabilities on a Pepper robot to build an interaction model that stores the interpretations of perceptions and conversations in combination with provenance on its sources. The robot learns directly from what people tell it, possibly in relation to its perception. We demonstrate how the robot’s communication is driven by hunger to acquire more knowledge from and on people and objects, to resolve uncertainties and conflicts, and to share awareness of the perceived environment. Likewise, the robot can make reference to the world and its knowledge about the world and the encounters with people that yielded this knowledge.
Robots, VU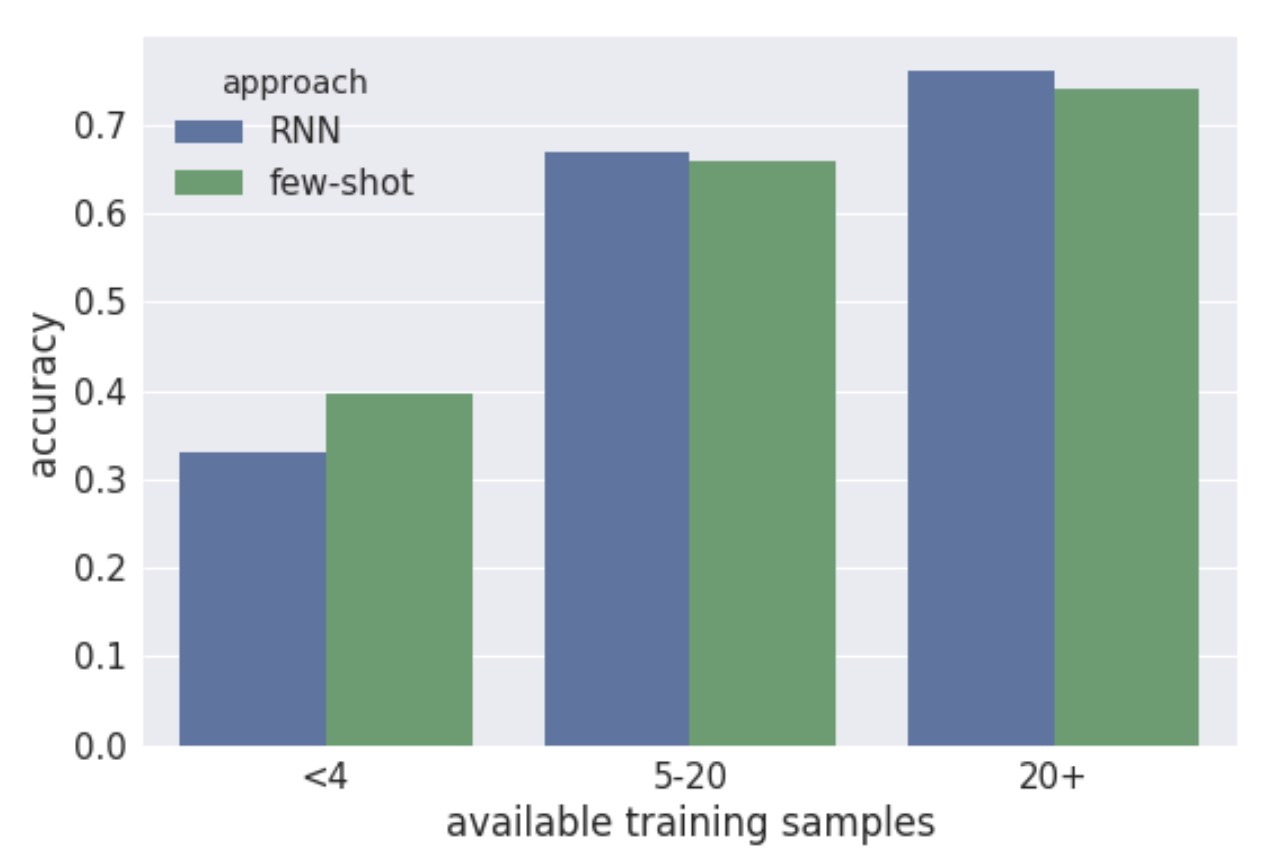
This paper describes the system that team MYTOMORROWS-TU DELFT developed for the 2019 Social Media Mining for Health Applications (SMM4H) Shared Task 3, for the end-to-end normalization of ADR tweet mentions to their corresponding MEDDRA codes. For the first two steps, we reuse a state-of-theart approach, focusing our contribution on the final entity-linking step. For that we propose a simple Few-Shot learning approach, based on pre-trained word embeddings and data from the UMLS, combined with the provided training data. Our system (relaxed F1: 0.337- 0.345) outperforms the average (relaxed F1 0.2972) of the participants in this task, demonstrating the potential feasibility of few-shot learning in the context of medical text normalization.
Health informatics, myTomorrows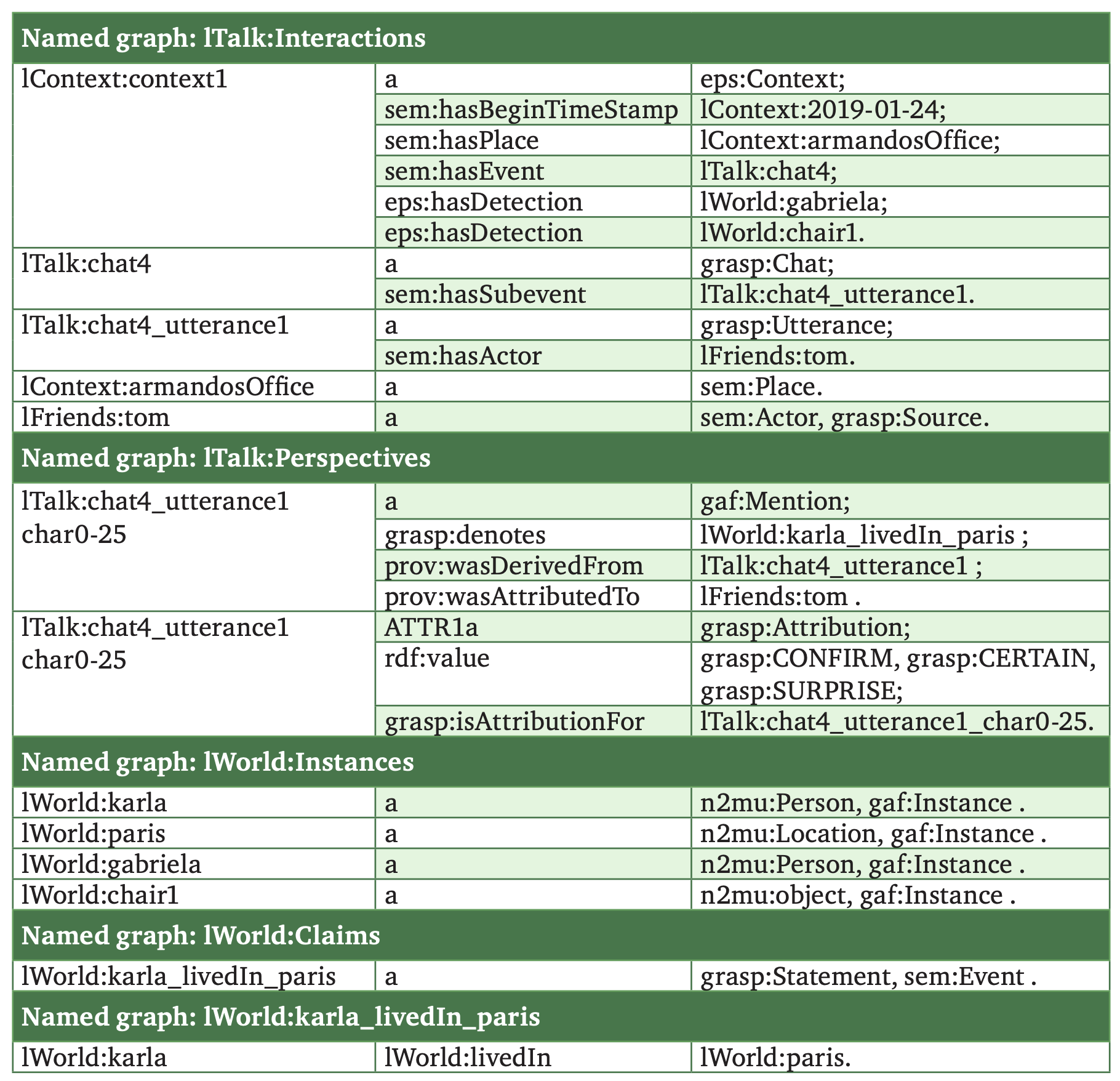
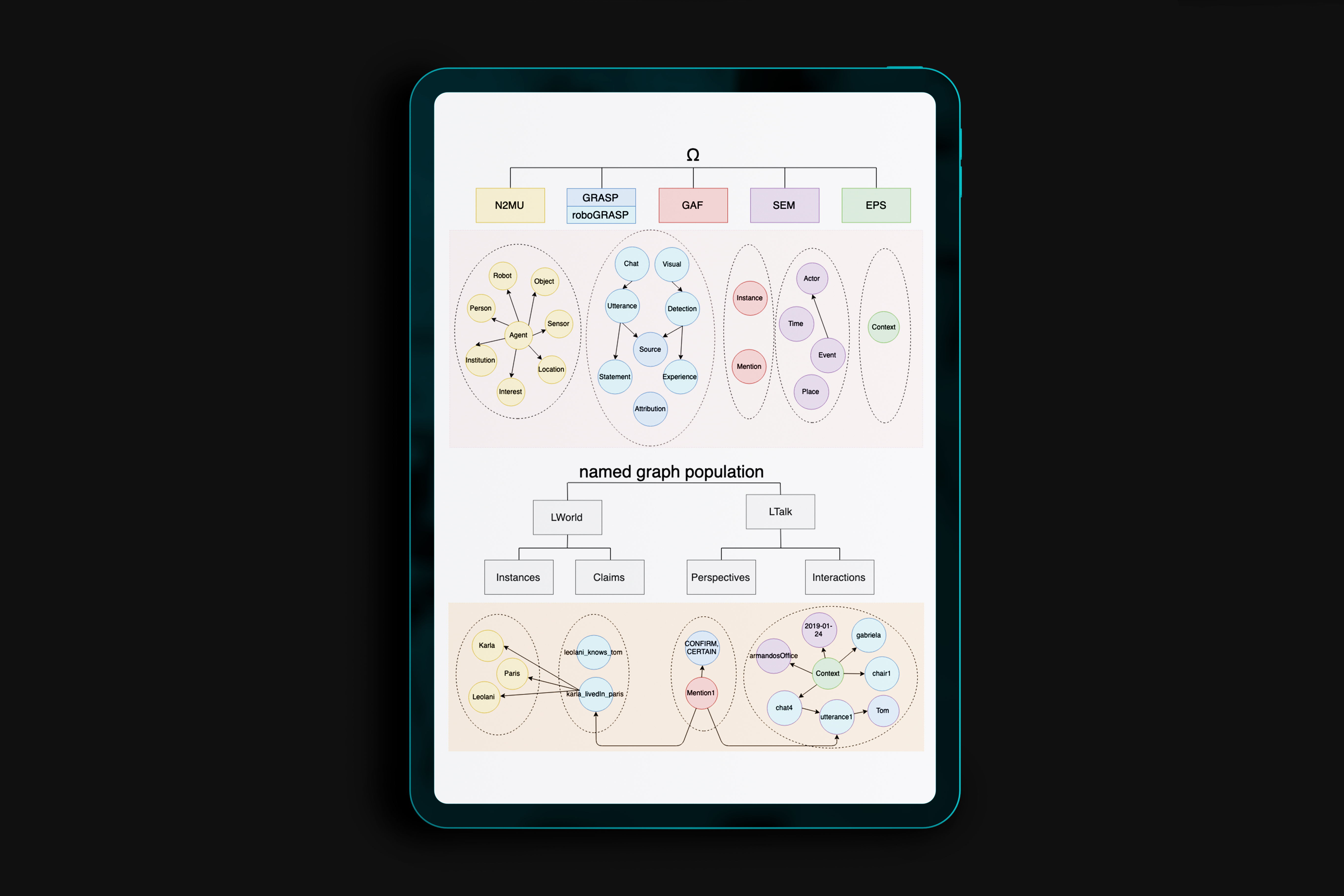
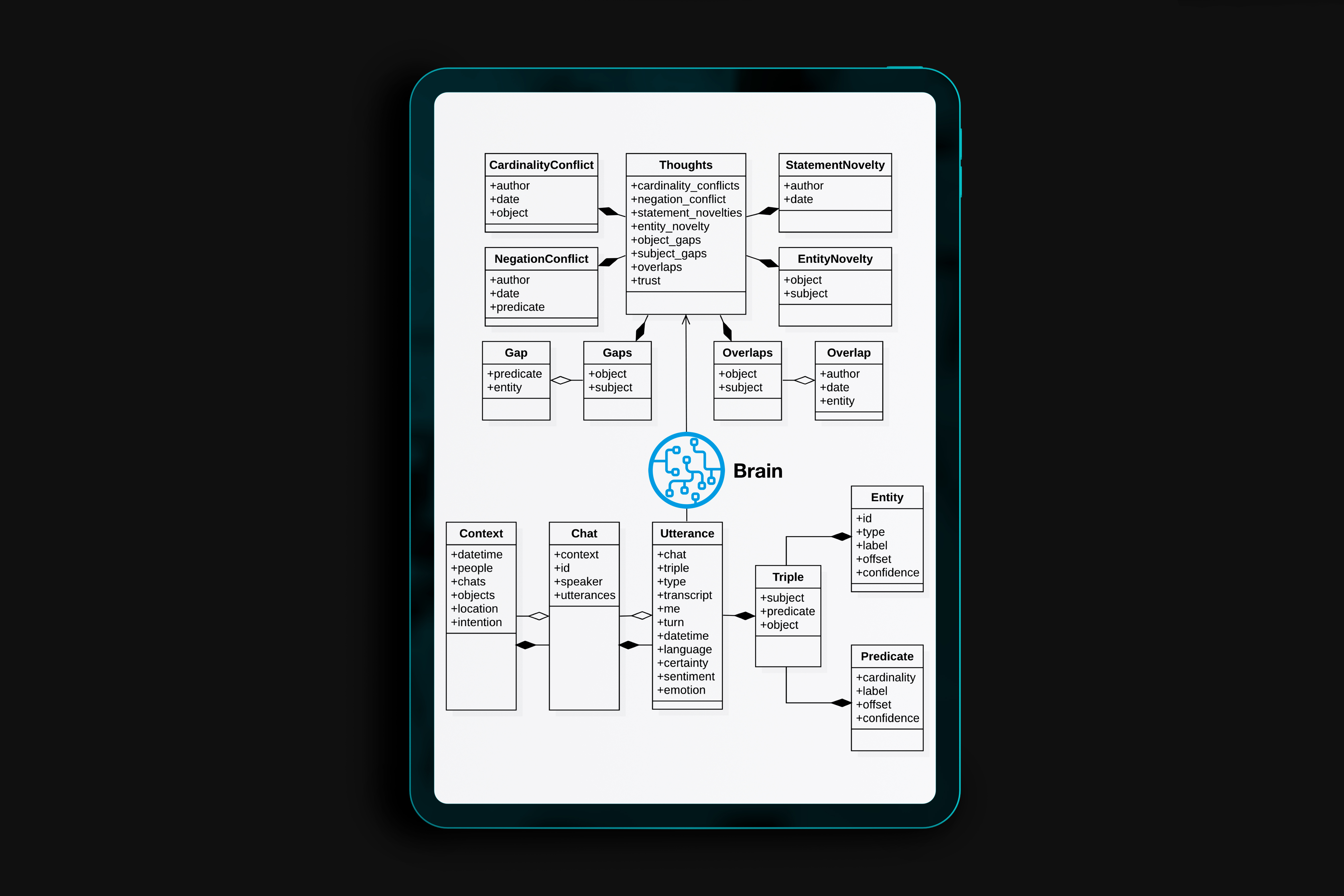
We describe a model for a robot that learns about the world and her companions through natural language communication. The model supports open-domain learning, where the robot has a drive to learn about new concepts, new friends, and new properties of friends and concept instances. The robot tries to fill gaps, resolve uncertainties and resolve conflicts. The absorbed knowledge consists of everything people tell her, the situations and objects she perceives and whatever she finds on the web. The results of her interactions and perceptions are kept in an RDF triple store to enable reasoning over her knowledge and experiences. The robot uses a theory of mind to keep track of who said what, when and where. Accumulating knowledge results in complex states to which the robot needs to respond. In this paper, we look into two specific aspects of such complex knowledge states: 1) reflecting on the status of the knowledge acquired through a new notion of thoughts and 2) defining the context during which knowledge is acquired. Thoughts form the basis for drives on which the robot communicates. We capture episodic contexts to keep instances of objects apart across different locations, which results in differentiating the acquired knowledge over specific encounters. Both aspects make the communication more dynamic and result in more initiatives by the robot.
Robots, VU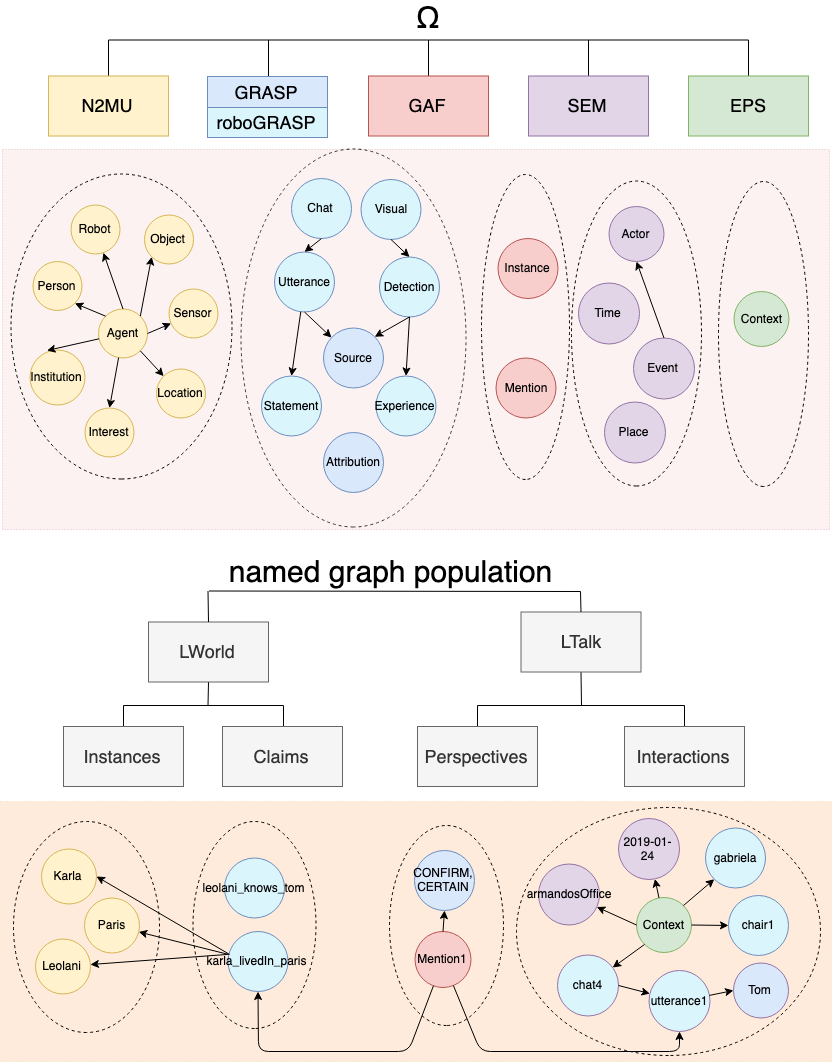
People and robots make mistakes and should therefore recognize and communicate about their“imperfectness” when they collaborate. In previous work [3, 2], we described a female robot model Leolani(L) that supports open-domain learning through natural language communication, having a drive to learn new information and build social relationships. The absorbed knowledge consists of everything people tell her and the situations and objects she perceives. For this demo, we focus on the symbolic representation of the resulting knowledge. We describe how L can query and reason over her knowledge and experiences as well as access the Semantic Web. As such, we envision L to become a semantic agent which people could naturally interact with.
Robots, VU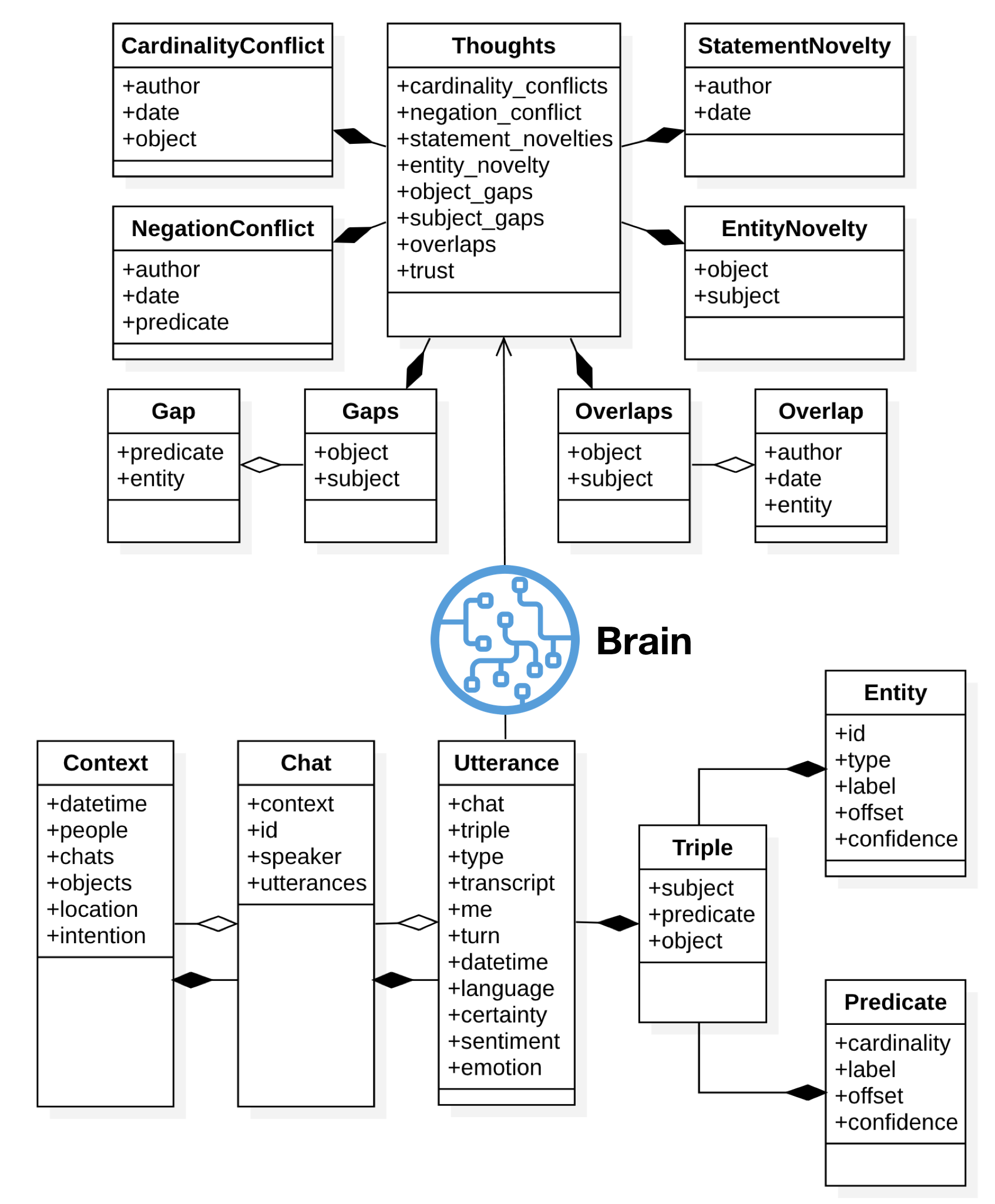
This paper presents a model of contextual awareness implemented for a social communicative robot Leolani. Our model starts from the assumption that robots and humans need to establish a common ground about the world they share. This is not trivial as robots make many errors and start with little knowledge. As such, the context in which communication takes place can both help and complicate the interaction: if the context is interpreted correctly it helps in disambiguating the signals, but if it is interpreted wrongly it may distort interpretation. We defined the surrounding world as a spatial context, the communication as a discourse context and the interaction as a social context, which are all three interconnected and have an impact on each other. We model the result of the interpretations as symbolic knowledge (RDF) in a triple store to reason over the result, detect conflicts, uncertainty and gaps. We explain how our model tries to combine the contexts and the signal interpretation and we mention future directions of research to improve this complex process.
Robots, VU
Language identification remains a challenge for short texts originating from social media. Moreover, domain specific terminology, which is frequent in the medical domain, may not change cross-linguistically, making language identification even more difficult. We conducted language identification on four datasets, two of them with general language, and two of them containing medical language. We evaluated the impact of two embedding representations and a set of linguistic features based on graphotactics. The proposed linguistic features reflect the graphotactics of the languages included in the test dataset. For classification, we implemented two algorithms: random forest and SVM. Our findings show that, when classifying general language, linguistic-based features perform close to the embedding representations of fastText and BERT. However, when classifying text with technical terms, the linguistic features outperform embedding representations. The combination of embeddings with linguistic features had a positive impact on the classification task under both settings. Therefore, our results suggest that these linguistic features could be applied for big and small datasets keeping the good performances in both general and medical languages. As future work, we want to test the linguistic features for a more significant set of languages.
Health informatics, myTomorrows
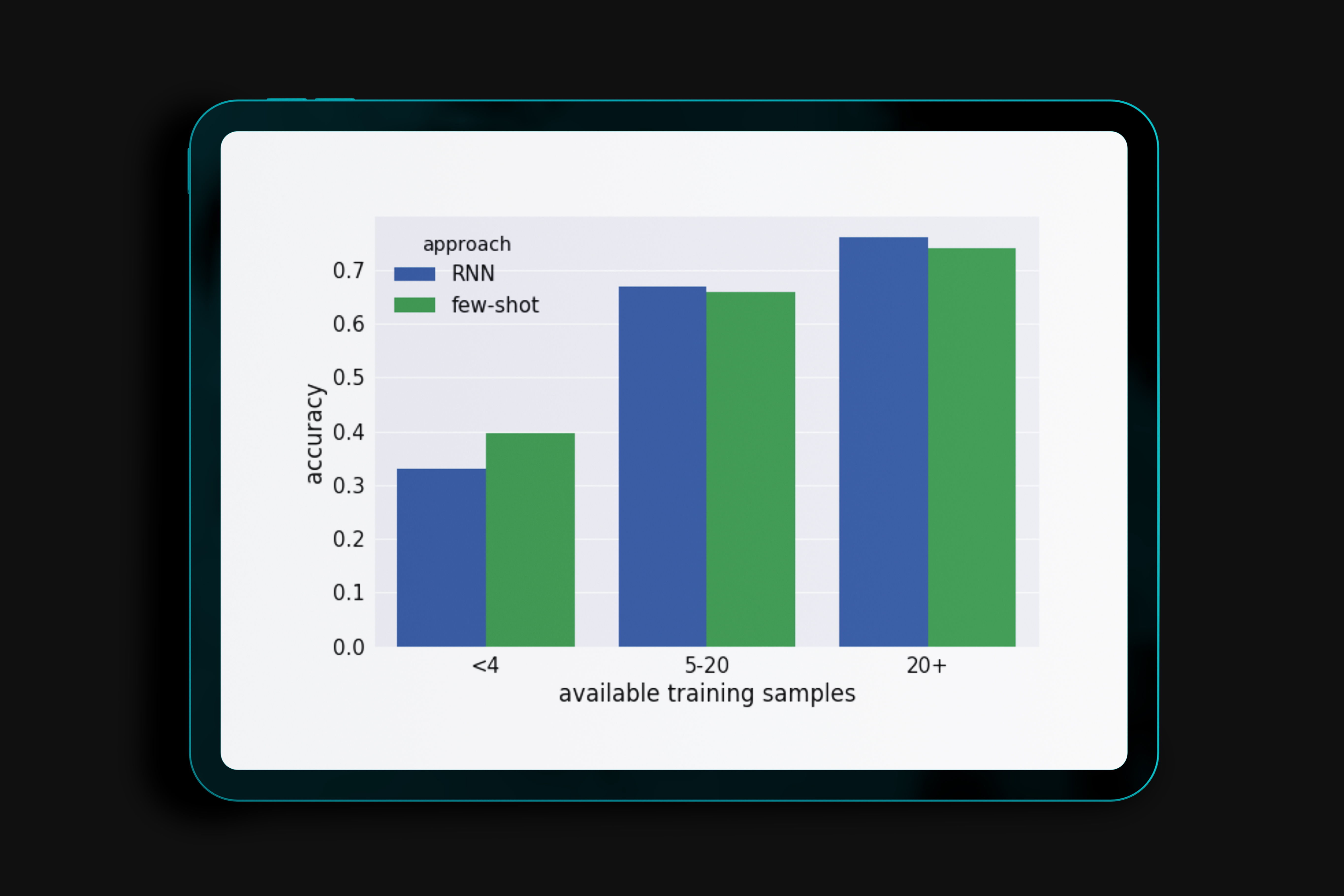
The automatic mapping of Adverse Drug Reaction (ADR) reports from user-generated content to concepts in a controlled medical vocabulary provides valuable insights for monitoring public health. While state-of-the-art deep learning-based sequence classification techniques achieve impressive performance for medical concepts with large amounts of training data, they show their limit with long-tail concepts that have a low number of training samples. The above hinders their adaptability to the changes of layman’s terminology and the constant emergence of new informal medical terms. Our objective in this paper is to tackle the problem of normalizing long-tail ADR mentions in user-generated content. In this paper, we exploit the implicit semantics of rare ADRs for which we have few training samples, in order to detect the most similar class for the given ADR. The evaluation results demonstrate that our proposed approach addresses the limitations of the existing techniques when the amount of training data is limited.
Health informatics, myTomorrows
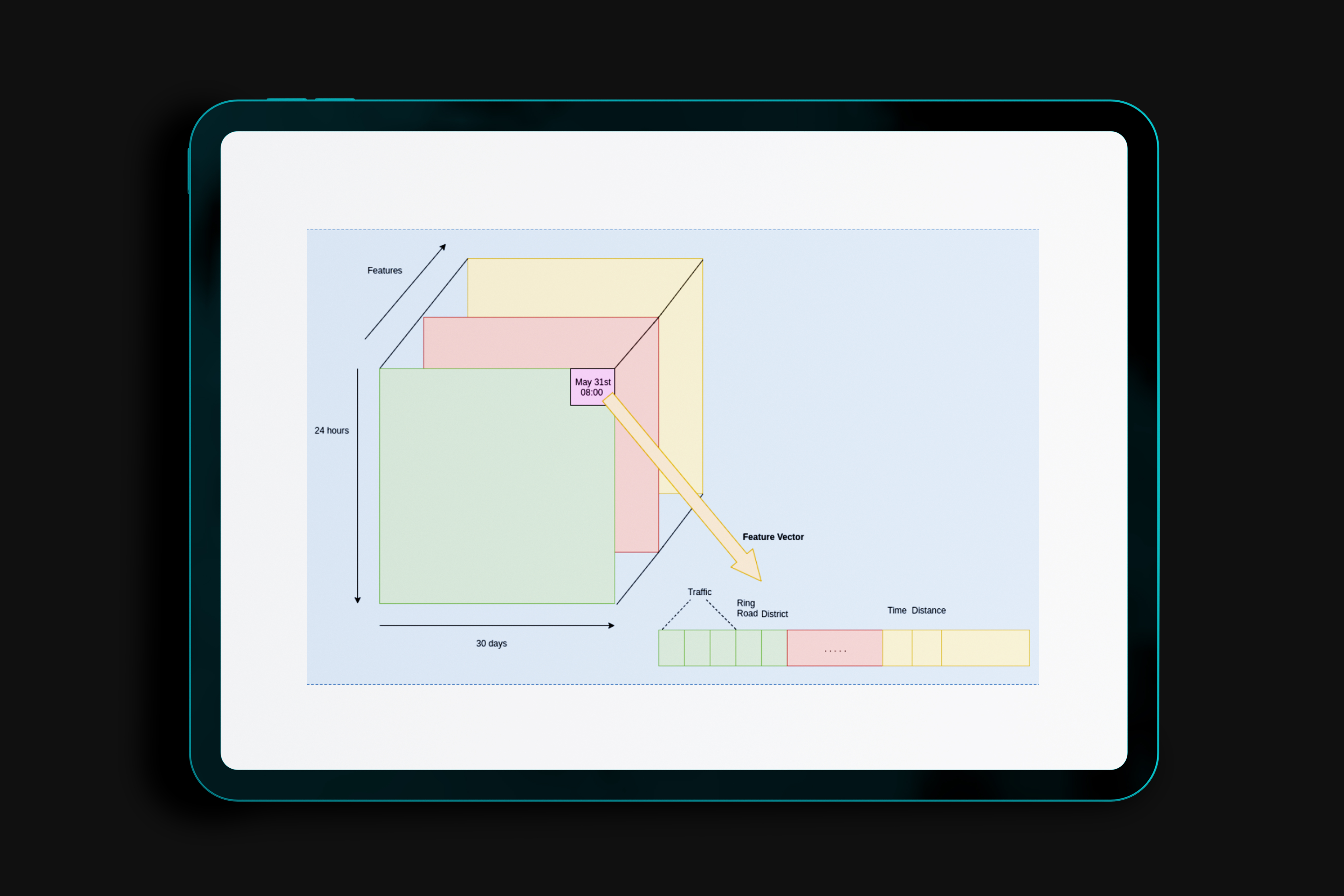
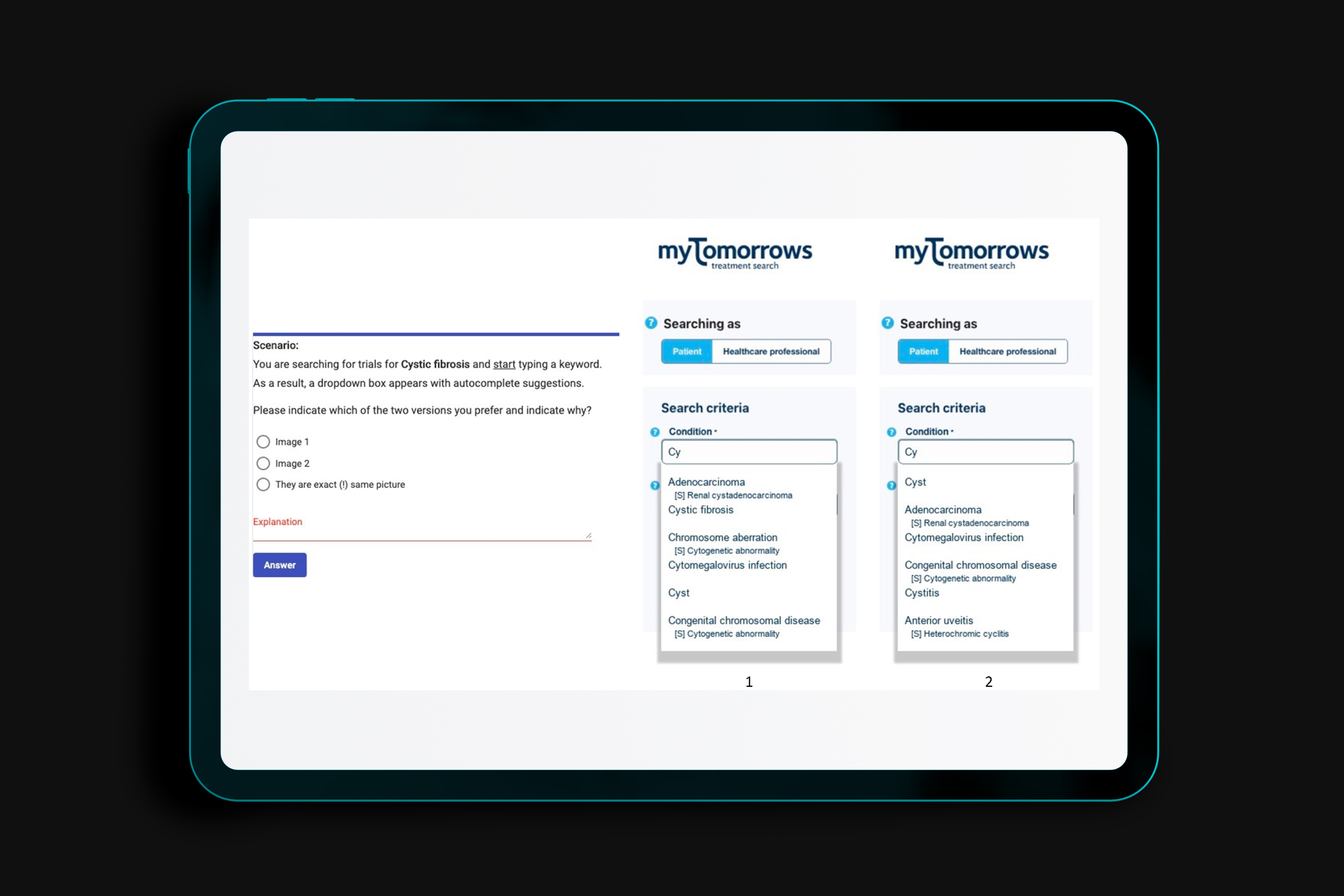
Query popularity is a main feature in web-search auto-completion. Several personalization features have been proposed to support specific users’ searches, but often do not meet the privacy requirements of a medical environment (e.g. clinical trial search). Furthermore, in such specialized domains, the differences in user expertise and the domain-specific language users employ are far more widespread than in web-search. We propose a query auto-completion method based on different relevancy and diversity features, which can appropriately meet different user needs. Our method incorporates indirect popularity measures, along with graph topology and semantic features. An evolutionary algorithm optimizes relevance, diversity, and coverage to return a top-k list of query completions to the user. We evaluated our approach quantitatively and qualitatively using query log data from a clinical trial search engine, comparing the effects of different relevancy and diversity settings using domain experts. We found that syntax-based diversity has more impact on effectiveness and efficiency, graph-based diversity shows a more compact list of results, and relevancy the most effect on indicated preferences.
Health informatics, myTomorrows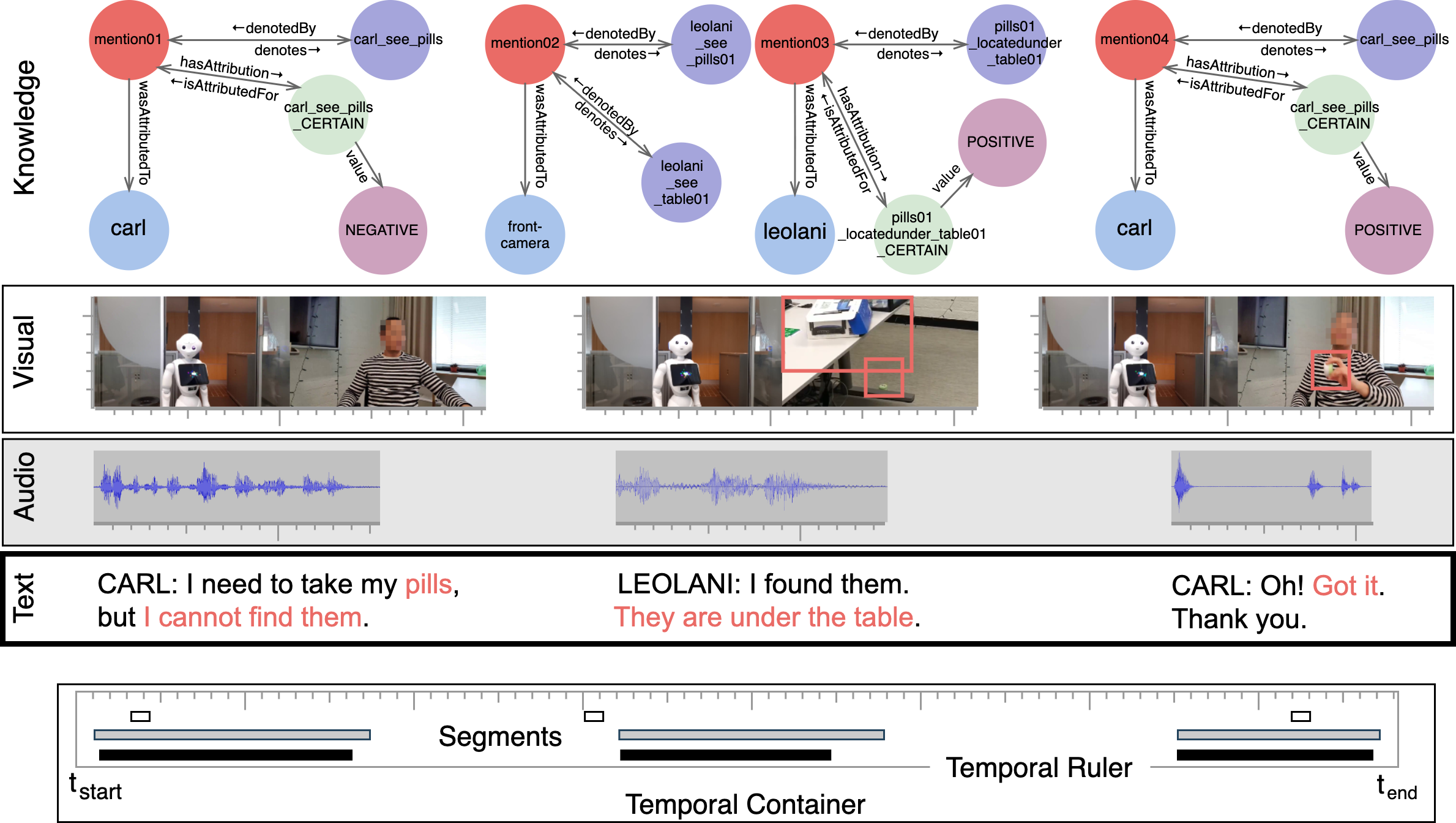
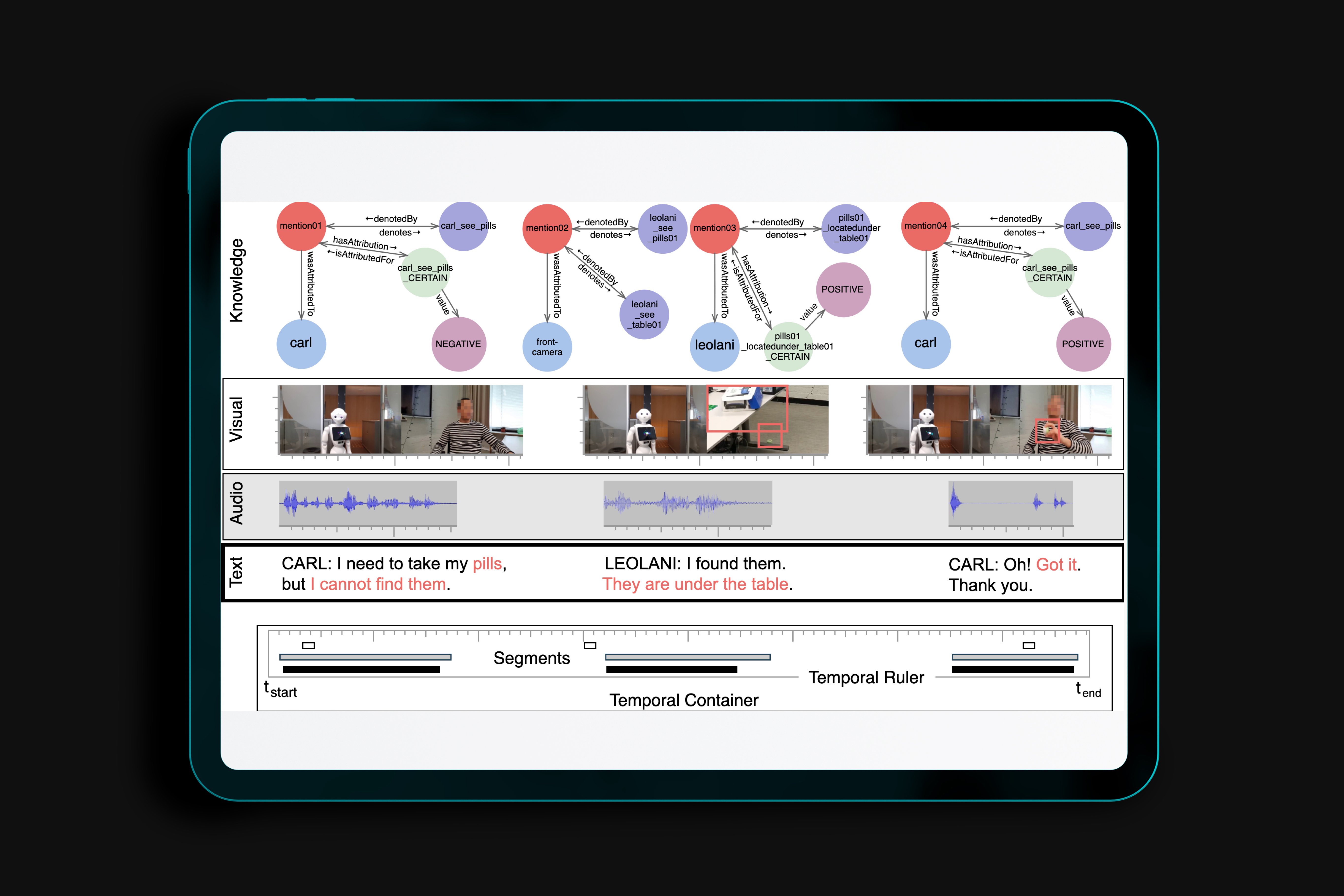
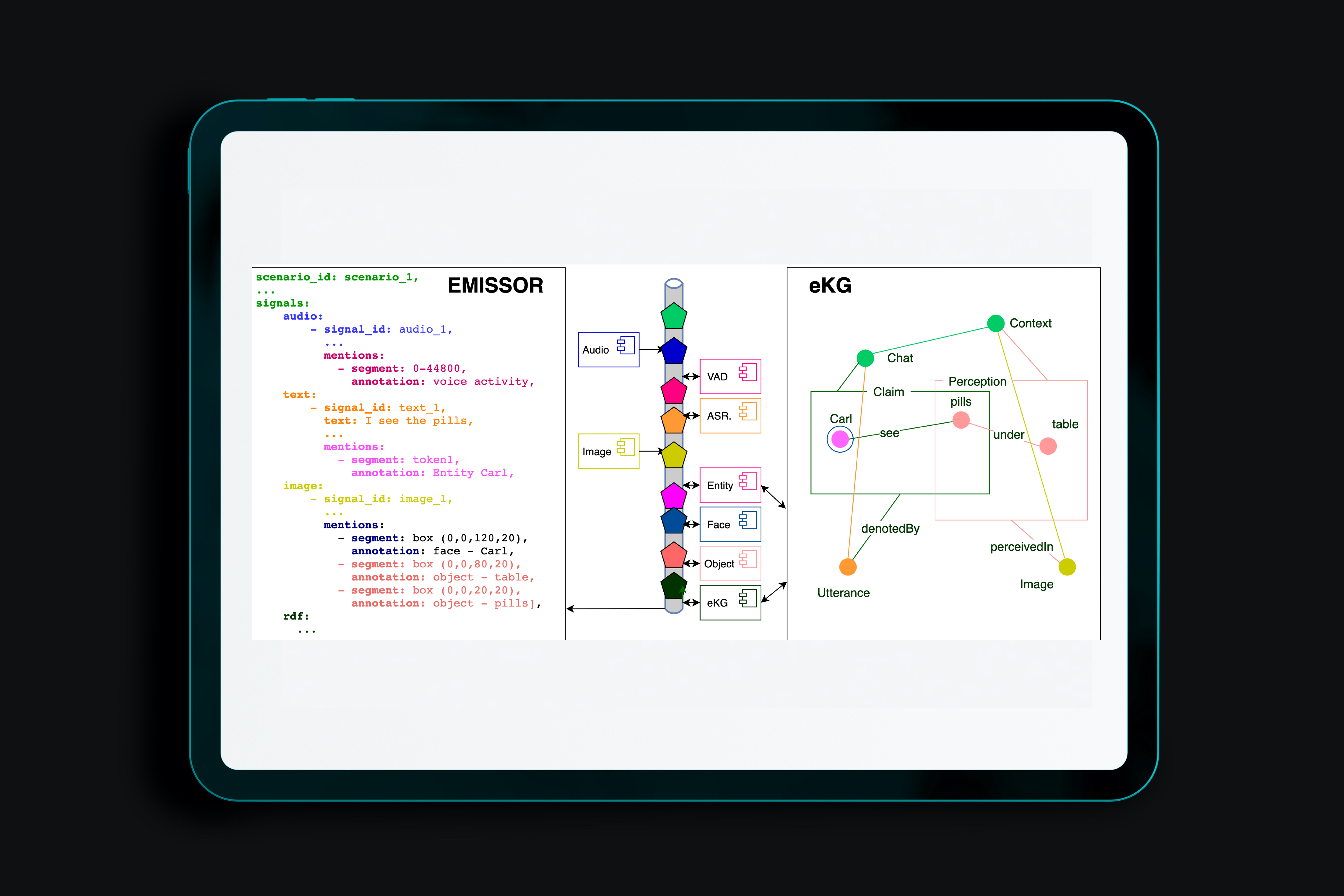
We present EMISSOR: a platform to capture multimodal interactions as recordings of episodic experiences with explicit referential interpretations that also yield an episodic Knowledge Graph (eKG). The platform stores streams of multiple modalities as parallel signals. Each signal is segmented and annotated independently with interpretation. Annotations are eventually mapped to explicit identities and relations in the eKG. As we ground signal segments from different modalities to the same instance representations, we also ground different modalities across each other. Unique to our eKG is that it accepts different interpretations across modalities, sources and experiences and supports reasoning over conflicting information and uncertainties that may result from multimodal experiences. EMISSOR can record and annotate experiments in virtual and real-world, combine data, evaluate system behavior and their performance for preset goals but also model the accumulation of knowledge and interpretations in the Knowledge Graph as a result of these episodic experiences.
Robots, VU
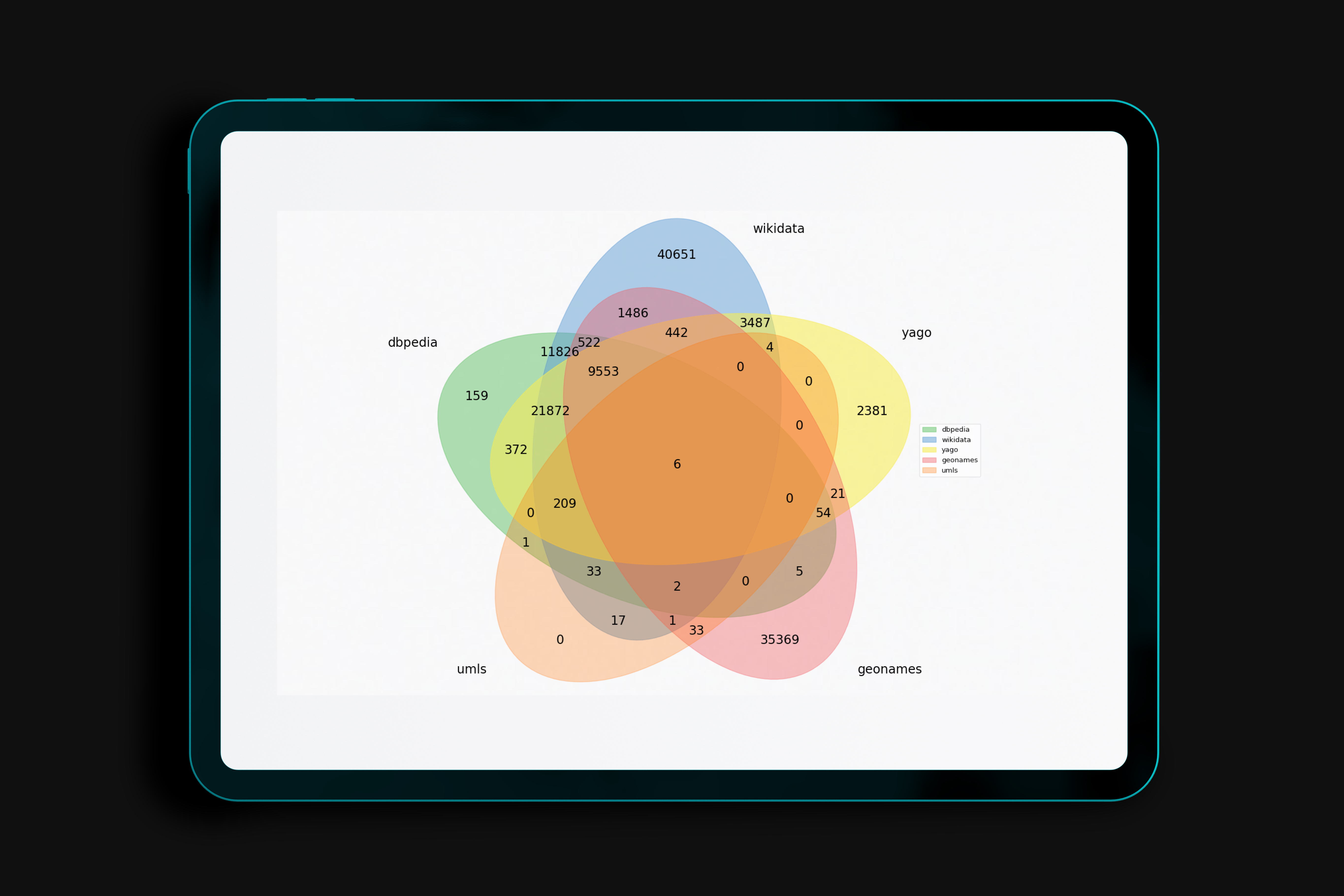
\textbf{Background}: Access to medical care is strongly dependent on resource allocation, such as the geographical distribution of medical facilities. Nevertheless, this data is usually restricted to country official documentation, not available to the public. While some medical facilities' data is accessible as semantic resources on the Web, it is not consistent in its modeling and has yet to be integrated into a complete, open, and specialized repository. This work focuses on generating a comprehensive semantic dataset of medical facilities worldwide containing extensive information about such facilities' geo-location. \textbf{Results}: For this purpose, we collect, align, and link various open-source databases where medical facilities' information may be present. This work allows us to evaluate each data source along various dimensions, such as completeness, correctness, and interlinking with other sources, all critical aspects of current knowledge representation technologies. \textbf{Conclusions}: Our contributions directly benefit stakeholders in the biomedical and health domain (patients, healthcare professionals, companies, regulatory authorities, and researchers), who will now have a better overview of the access to and distribution of medical facilities.
Health Informatics, myTomorrows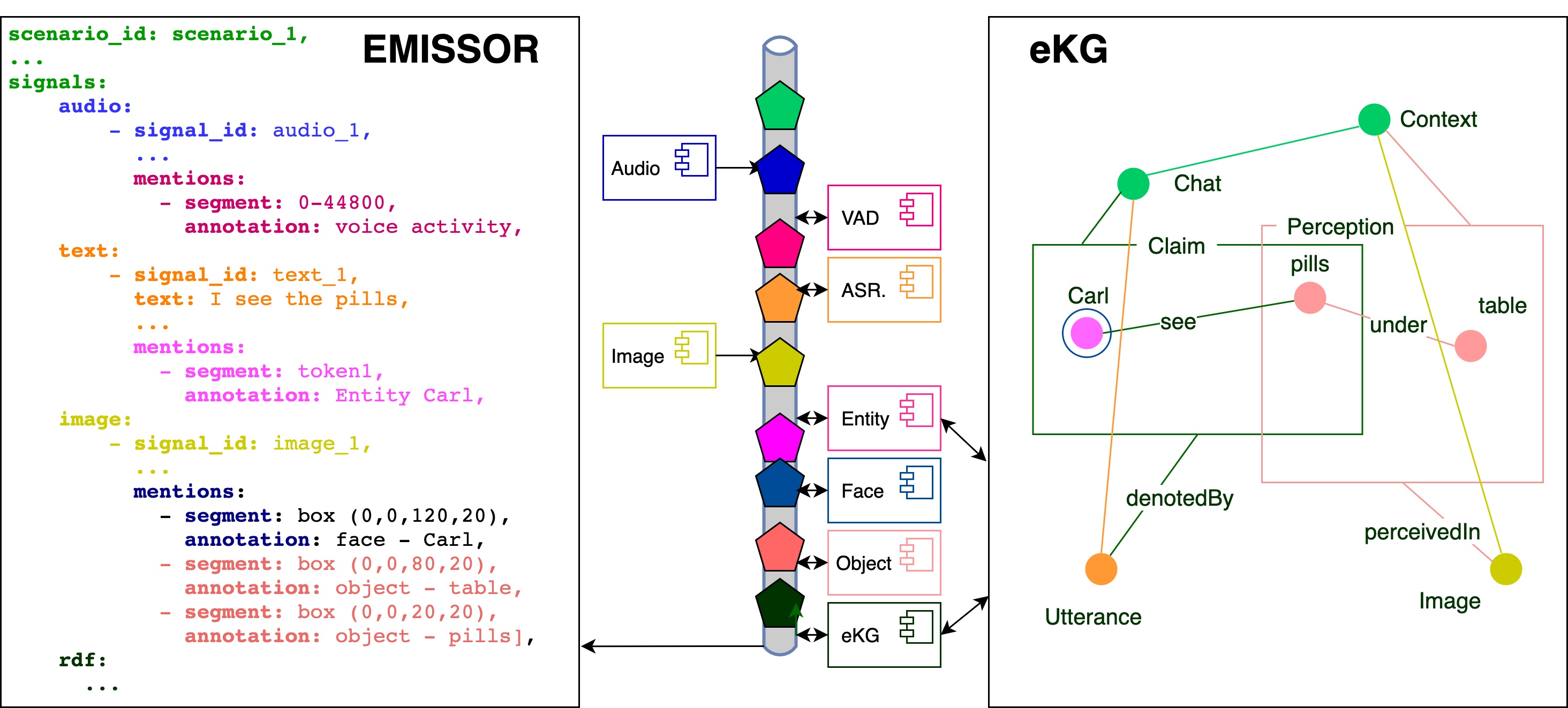
The paper describes a flexible and modular platform to create multimodal interactive agents. The platform operates through an event-bus on which signals and interpretations are posted in a sequence in time. Different sensors and interpretation components can be integrated by defining their input and output as \textit{topics}, which results in a logical workflow for further interpretations. We explain a broad range of components that have been developed so far and integrated into a range of interactive agents. We also explain how the actual interaction is recorded as multimodal data as well as in a so-called episodic Knowledge Graph. By analysing the recorded interaction, we can analyse and compare different agents and agent components.
Robots, VU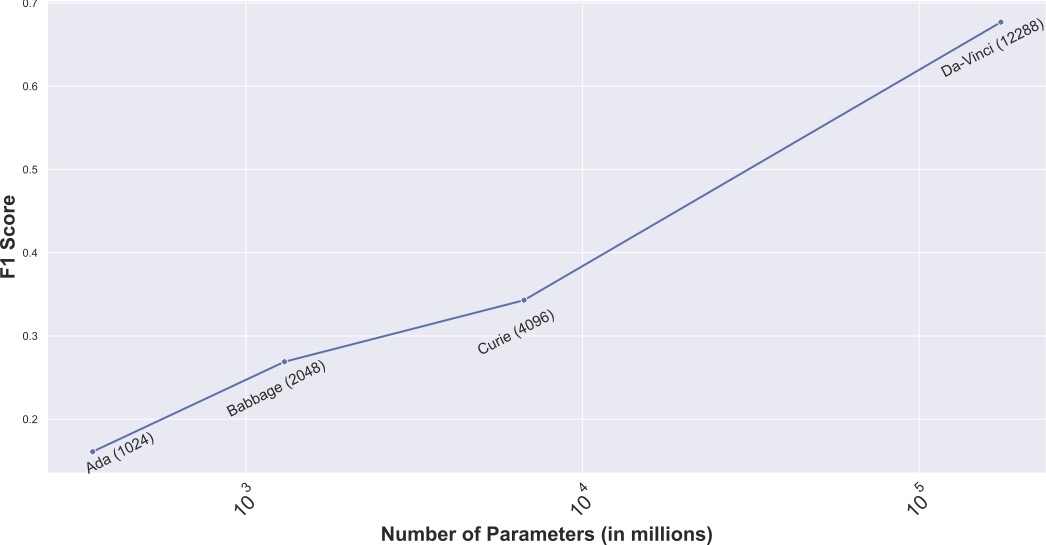
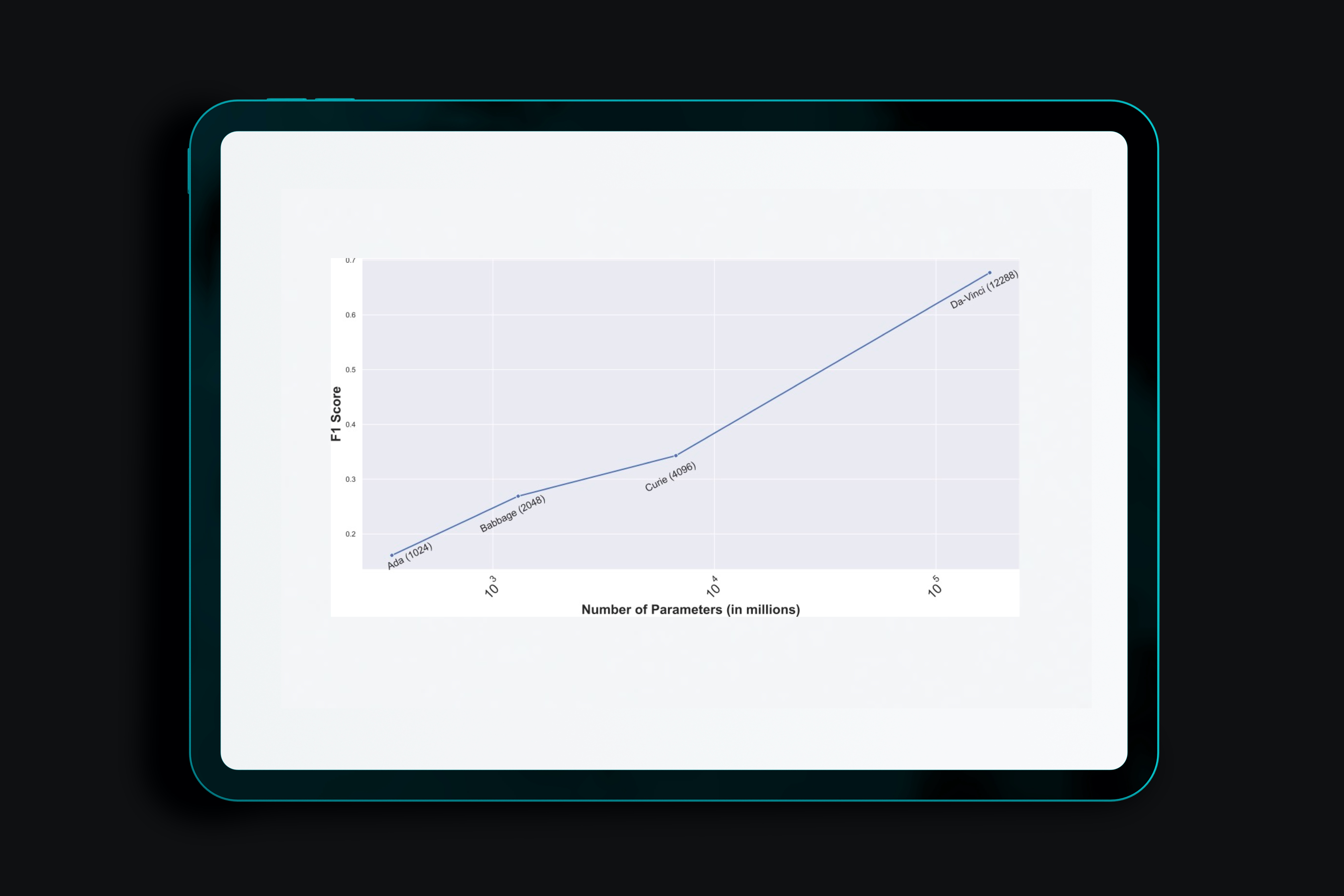
Language Models (LMs) have proven to be useful in various downstream applications, such as summarisation, translation, question answering and text classification. LMs are becoming increasingly important tools in Artificial Intelligence, because of the vast quantity of information they can store. In this work, we present ProP (Prompting as Probing), which utilizes GPT-3, a large Language Model originally proposed by OpenAI in 2020, to perform the task of Knowledge Base Construction (KBC). ProP implements a multi-step approach that combines a variety of prompting techniques to achieve this. Our results show that manual prompt curation is essential, that the LM must be encouraged to give answer sets of variable lengths, in particular including empty answer sets, that true/false questions are a useful device to increase precision on suggestions generated by the LM, that the size of the LM is a crucial factor, and that a dictionary of entity aliases improves the LM score. Our evaluation study indicates that these proposed techniques can substantially enhance the quality of the final predictions: ProP won track 2 of the LM-KBC competition, outperforming the baseline by 36.4 percentage points. Our implementation is available on https://github.com/HEmile/iswc-challenge.
Graph Technologies, VU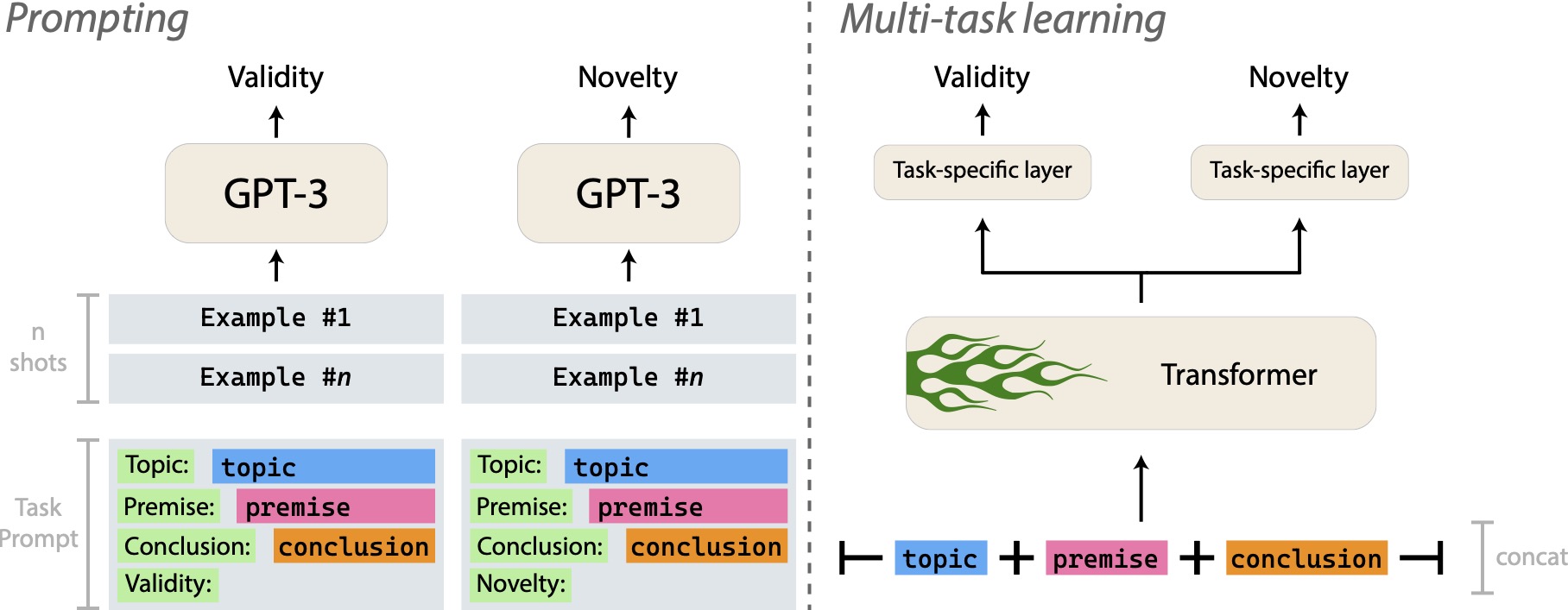
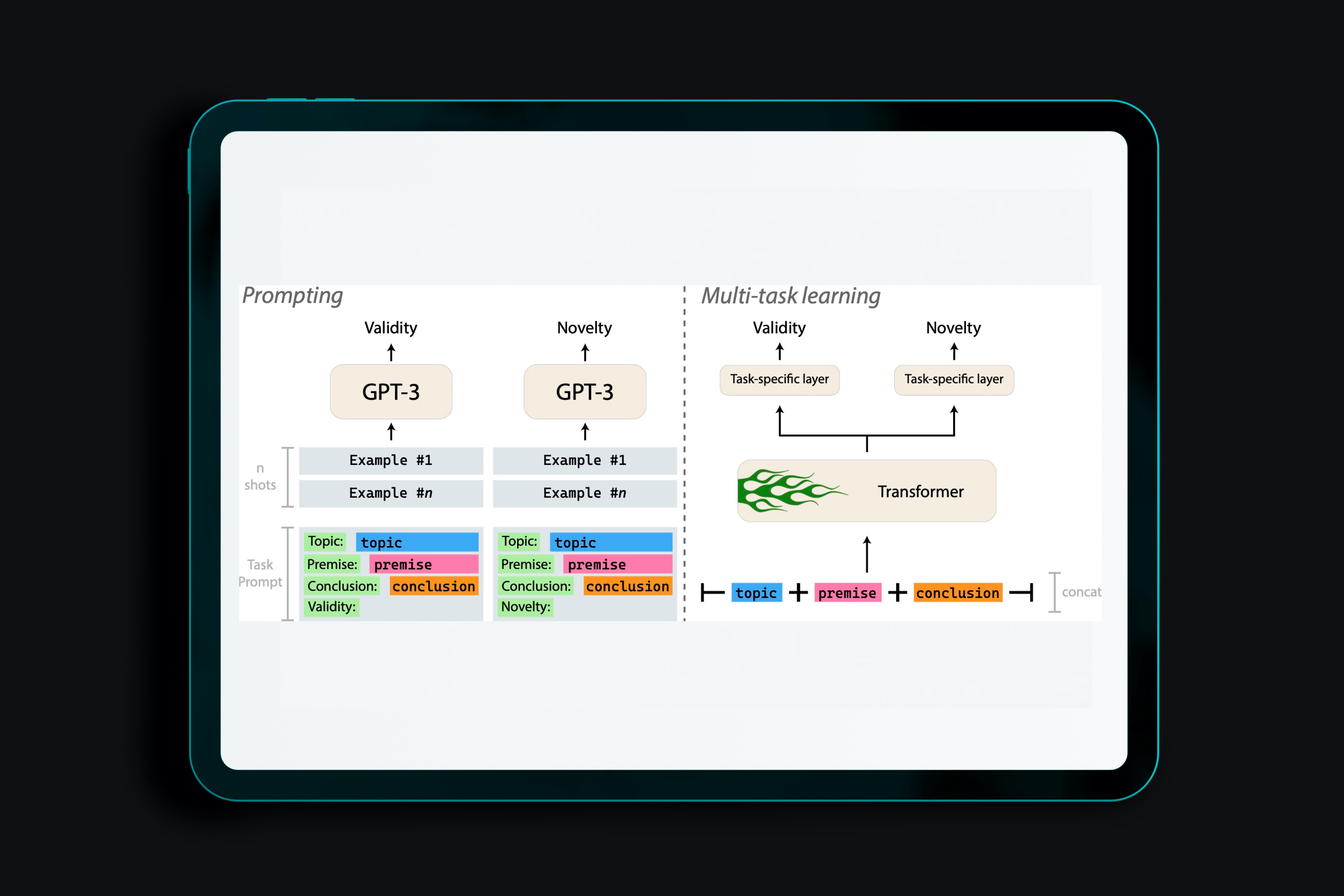
This paper describes our contributions to the Shared Task of the 9th Workshop on Argument Mining (2022). Our approach focuses on the application of Large Language Models to the task of Argument Quality Prediction. We perform prompt engineering using GPT-3, and further investigate training paradigms like multi-task learning, contrastive learning, and intermediate-task training. We find that a mixed prediction setup outperforms single models. Prompting GPT-3 works best for predicting argument validity, and argument novelty is best estimated by a model trained using all three training paradigms (intermediate task training, multi-task learning, and contrastive learning).
Health informatics, myTomorrows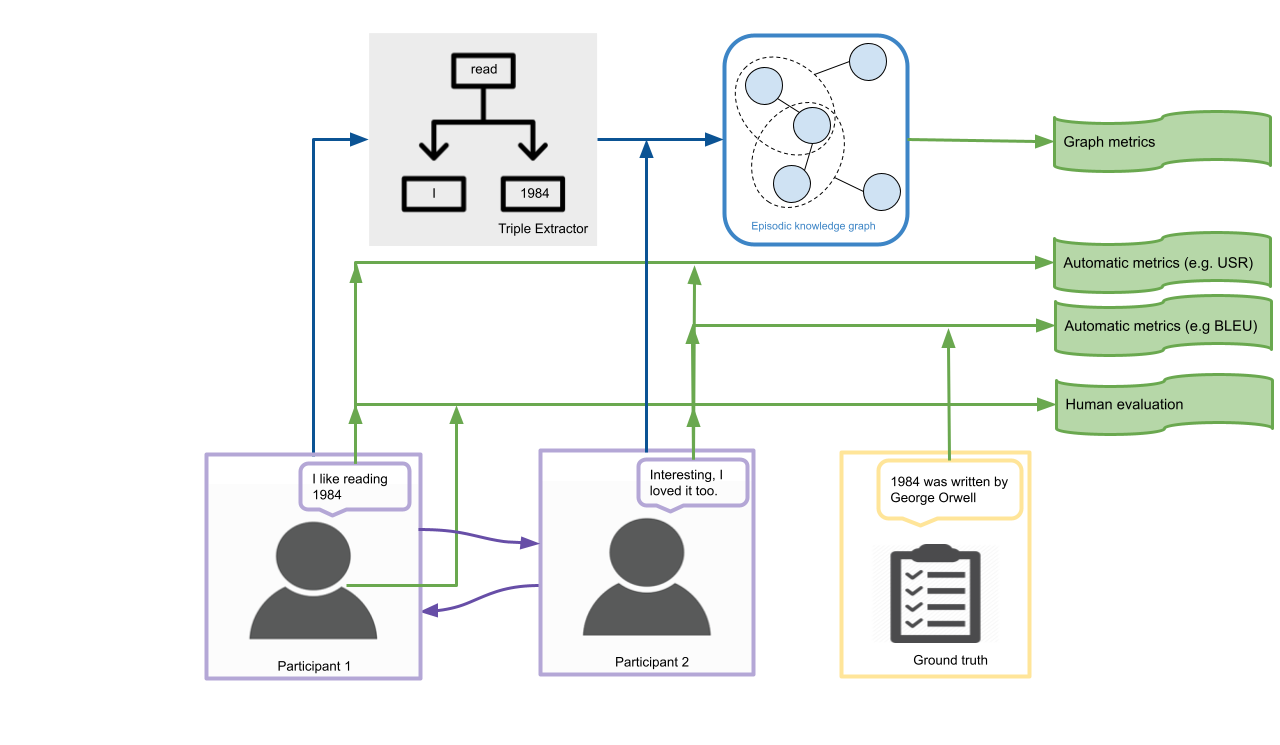
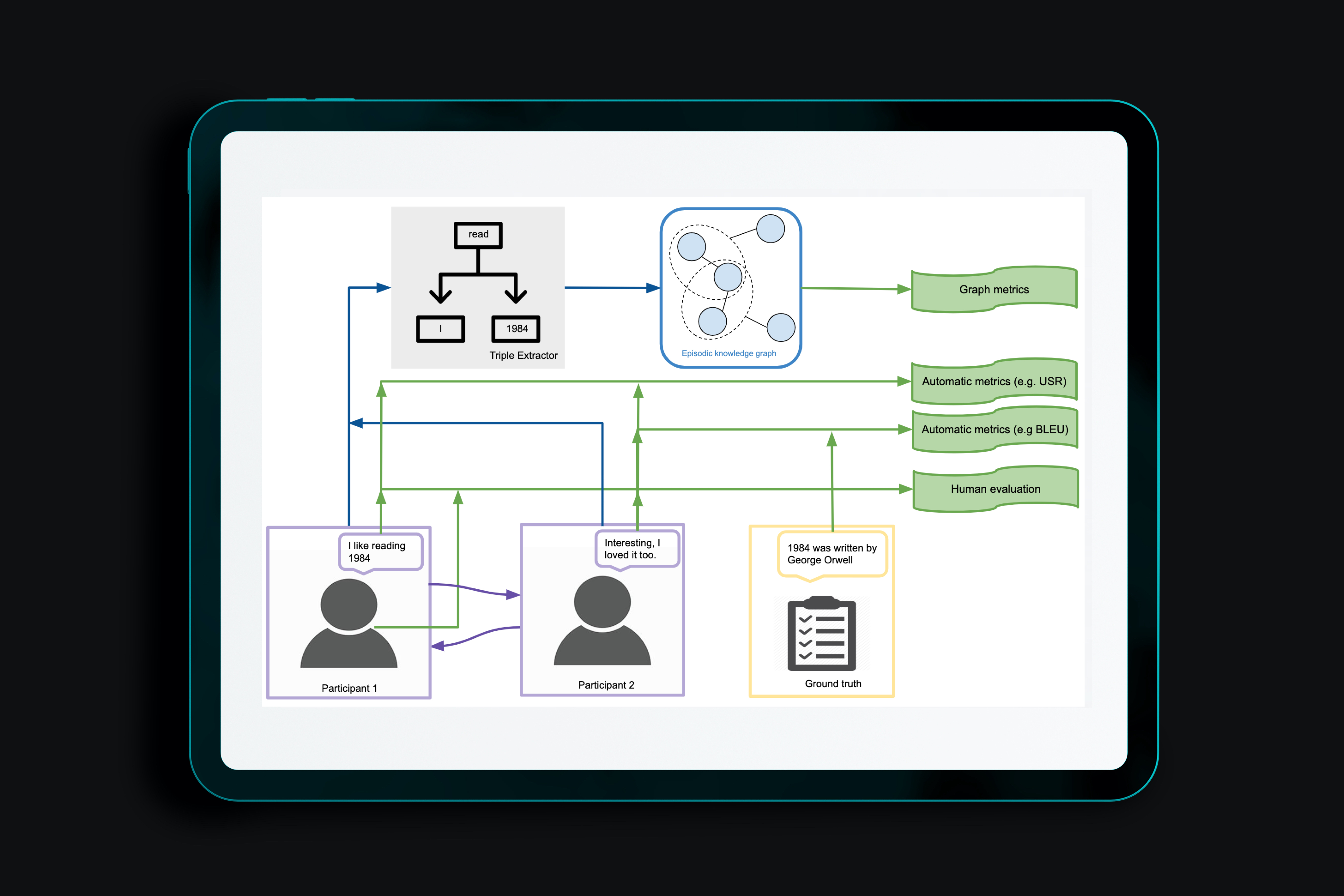
We present a new method based on episodic Knowledge Graphs (eKGs) for evaluating (multimodal) conversational agents in open domains. This graph is generated by interpreting raw signals during conversation and is able to capture the accumulation of knowledge over time. We apply structural and semantic analysis of the resulting graphs and translate the properties into qualitative measures. We compare these measures with existing automatic and manual evaluation metrics commonly used for conversational agents. Our results show that our Knowledge-Graph-based evaluation provides more qualitative insights into interaction and the agent's behavior.
Robots, VU